quadipy
quadipy is a python package to help transform structured data into RDF graph format.
We built quadipy to enable developers to build a config based ingestion pipeline to an RDF data store (think like FiveTran or Stitch but for RDF). quadipy won't explcitly handle connections to different systems but will allow you to configure the RDF data you want to create from any data source. quadipy leverages RDFLib to pythonically structure RDF data.
The goal with this project is to enable transforming any tabular data structure into graph based RDF data. We go into depth here on how we have used this config based system to build out our internal knowledge graph at Vouch!
An example below shows what we mean by translating some tabular data into RDF graph data.
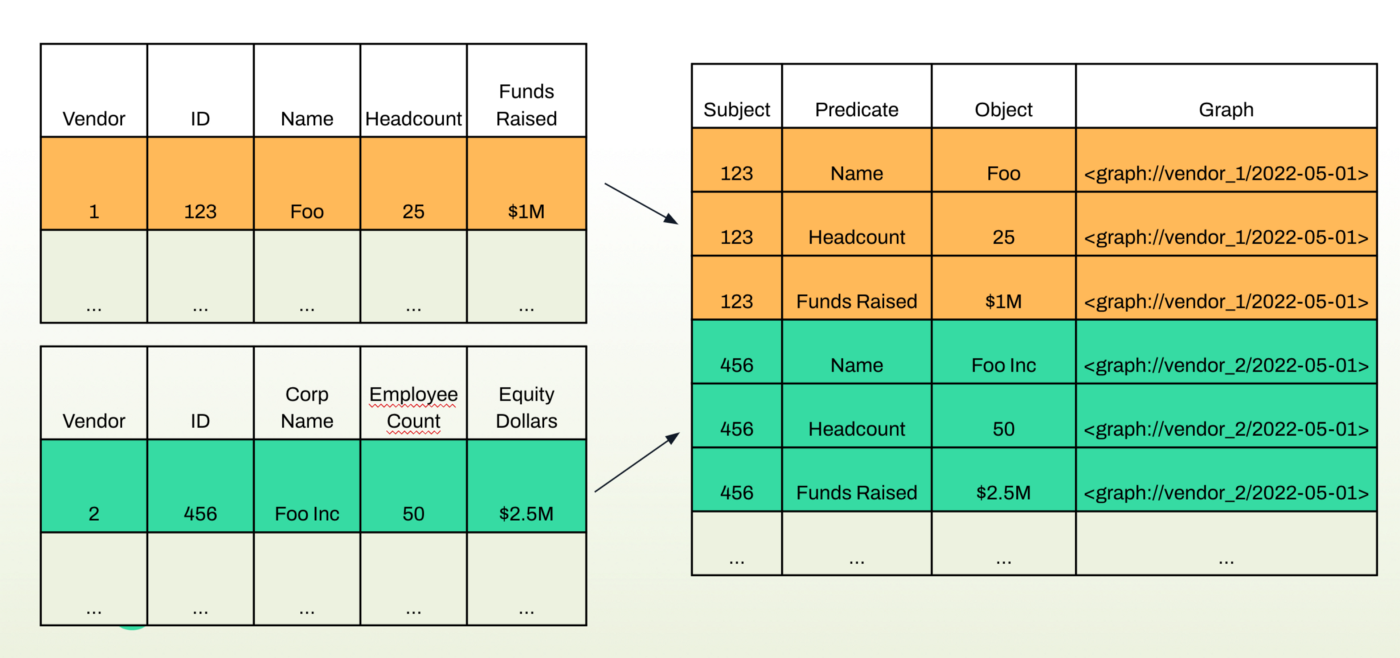
For a step by step walk-through of how to do this with more examples, visit tutorials
Dev Setup
Run to set up your dev enviornment
make setup
Usage
from quadipy import GraphFormatConfig
config = GraphFormatConfig.parse_file("path/to/config.json")
quads = [config.quadify(record) for record in records] # records is an Iterator[Dict]
quadipy can work with a variety of different data sources as long as what is sent to the quadify method is a Dict
Each Quad created has a .to_tuple() method that converts it to a tuple to help facilitate working with RDFLib Graphs
from rdflib import URIRef, Graph
from quadipy import Quad
quad = Quad(subject=URIRef("Alice"), predicate=URIRef("knows"), obj=URIRef("Bob"), graph=None)
g = Graph()
g.add(quad.to_tuple())
Setting up a GraphFormatConfig
The main value of quadipy comes from the GraphFormatConfig, which takes in a few parameters to configure the transformation of your data into RDF graph format. We provide configuration examples in the examples directory to help you get started. The full list of fields that can be configured is described below:
| field | required | description |
|---|---|---|
source_name |
Yes | A string that is used to describe the source (i.e. "wikipedia" for data from wikipedia) |
primary_key |
Yes | This is the key in your data that will be used for the subject of each value |
predicate_mapping |
Yes | A mapping where the keys are column names in your data source, and values a nested dict that required a predicate_uri key mapped to the RDF predicate in the target location and an optional obj_datatype key that maps to a custom datatype (currently we support [literal, uriref, or date]). If obj_datatype isn't specified, it will default to literal |
subject_namespace |
No | A string prepended to the quad's subject as a namespace, instead of just using the value of the primary_key. For example, for primary_key=123 and subject_namespace=wikipedia the values generated would NOT be URIRef("123") but URIRef("wikipedia/123") |
graph_namespace |
No | Similar to subject_namespace in that this will assign each fact to a named graph with the graph_namespace. This is useful to store metadata about fact provenance in named graphs. |
date_field |
No | The column in your dataset that the fact's "date" will be pulled from. When specified, the named graph field in each fact will be built from the date. For example if date_field=created_at and created_at='2021-01-01 in the source data the graph field will be URIRef("2021-01-01"). This can can work in conjunction with graph_namespace |
Validate Config files
To make sure the config files are valid, run the CLI by using the command
quadipy validate {path}
where path could be the directory for all the config files, e.g. examples or a single config file e.g. examples/simple.json
This script uses pydantic validator to make sure the config file is a valid JSON file, the required fields are presented and the predicate_uris are valid URIs ("valid" defined by RDFLib here)